The challenge of searching static websites is effectively a solved problem with brilliant, yet widely unadopted, solutions.
These projects scan and index your content at build time and ship it to the browser with the rest of your static files. No out-of-your-control external service required. A small library in JavaScript (sometimes accompanied by WebAssembly) loads the index and allows instant searching and works just fine offline. Searching the complete Federalist Papers for multiple keywords takes less than 100µs in my Wasm tech demo (I'll get to that later on).
The most popular libraries are written in JavaScript like Lunr, or Fuse, or FlexSearch. They provide pre-compiled indexes and fuzzy, wildcard, and boolean searches. They have good documentation and are ready for production usage.
But I'm more interested in how the up-and-coming Wasm-powered projects work. Browser search is a space where Wasm can really find an edge. Wasm runs faster, loads quicker, and ships smaller binaries (in theory, in practice it takes some work to get there).
The two projects I looked at both use Rust as a backend language:
- tinysearch generates a small, self-contained Wasm module (with an embedded index). It aims for a small memory footprint by using Bloom filters — a space-efficient probabilistic data structure that results in a negligible amount of false positives. Read more in A Tiny, Static, Full-Text Search Engine using Rust and WebAssembly by the creator, Matthias Endler.
- Stork focuses more on the developer experience with rich documentation and examples. Stork also pays keen attention to the user experience by providing a progress bar for loading the index, excerpts for the results (keywords highlighted), theme support, and more (see Embedding the Interface). Learn about how it came to life in Stork Turns One: Building a search tool for static sites with Rust and WebAssembly by the creator, James Little.
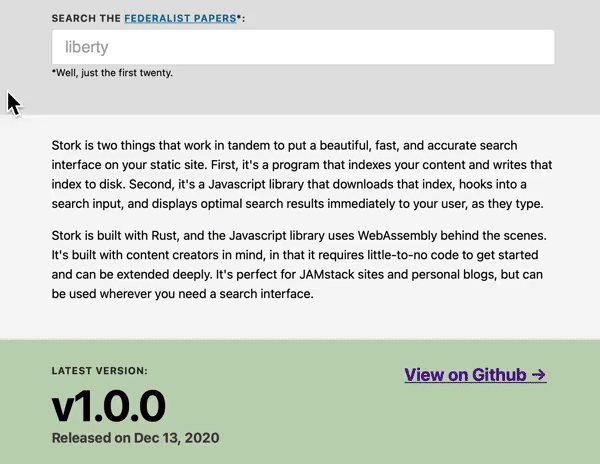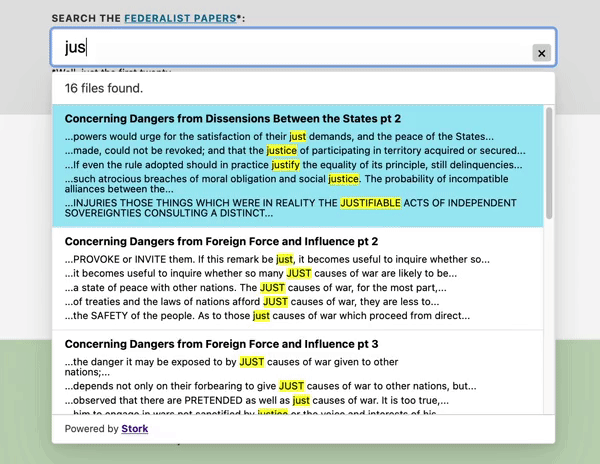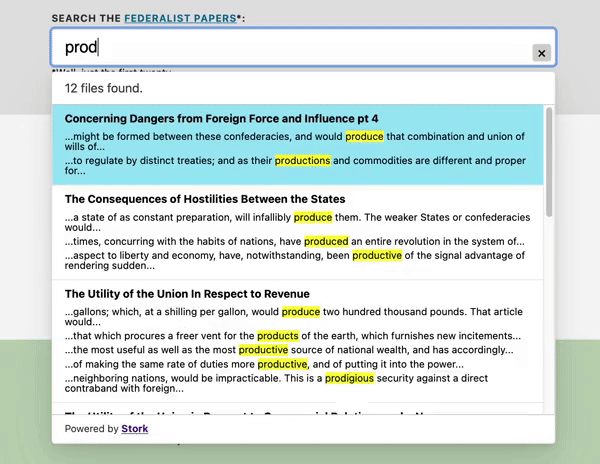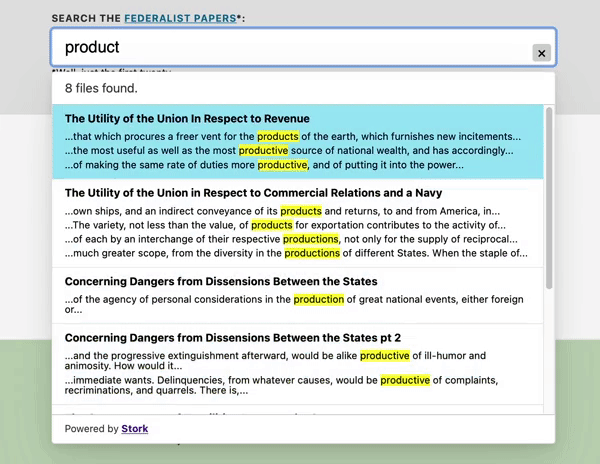
Stork is more interesting to me because it focuses on the human experience — of the person who builds with it, and the person who searches. See the thin, quick, configurable UI below.
In order to understand how these search tools work, and the design problems involved, I built a technical demo in Go, compiled to Wasm.
Technical Demo
My technical demo is inspired by Stork and uses a near-identical configuration file setup. So it had to be named after a bird 🐦 too — healeycodes/crane-search.
Crane is two programs. The first program scans a group of documents and builds an efficient index. 1MB of text and metadata is turned into a 25KB index (14KB gzipped). The second program is a Wasm module that is sent to the browser along with a little bit of JavaScript glue code and the index. The result is an instant search engine that helps users find web pages as they type.
The full-text search engine is powered in part with code from Artem Krylysov's blog post Let's build a Full-Text Search engine.
The core data-structure is an inverted index. It maps words to document IDs. This means we can check very quickly (i.e. 100µs within Wasm) which documents a word can be found in. At build time, we loop over the document files and add to the inverted index. We also create a list of results so we can relate a document ID to a document's metadata (defined in the configuration file). The metadata includes the title and URL so that we can display a list of search results in the browser.
We can return results for multiple keywords by looking at the common document IDs for each keyword. This takes linear time as the IDs are inserted into the index in order.
During the build stage, we perform normalization to make the search engine more helpful and accurate. For example, if you search for fish you probably want to match Fishing. Words are turned into lowercase, common words are dropped, and words are reduced into their root form (aka stemming — Krylysov's example code uses Snowball as a stemmer).
The document "Alice likes to go fishing" becomes ["alice", "go", "fish"]. The search term "Fishing" is also turned into a token, at search-time it becomes "fish".
To handle the document metadata, Crane's build program is passed the location of the configuration file. This tells it where to find the documents to index on disk, where they can be found on the static website, and what the search result should be titled.
[input]files = [{path = "docs/essays/essay01.txt",url = "essays/essay01.txt",title = "Introduction"},# etc.][output]filename = "dist/federalist.crane"
The index and result data is combined into a single struct called a store. It's encoded using encoding/gob, a binary encoding that is faster and smaller than JSON (one, two).
file, err := os.Create(config.Output.Filename)check(err)defer file.Close()encoder := gob.NewEncoder(file)store := search.Store{Index: index,Results: results,}err = encoder.Encode(store)check(err)
The second part of Crane is the program that's compiled into Wasm and sent to the browser. It uses the Go standard library package syscall/js.
Package js gives access to the WebAssembly host environment when using the js/wasm architecture. Its API is based on JavaScript semantics.
Our browser program makes two functions available in the global JavaScript scope. A new goroutine is spawned when they're called.
// Store is a shared type between both programs (build/browser)var store search.Storefunc main() {js.Global().Set("_craneLoad", js.FuncOf(load))js.Global().Set("_craneQuery", js.FuncOf(query))// Wait indefinitely,// required so that our Wasm module doesn't exit straight awayselect {}}func query(this js.Value, args []js.Value) interface{} {searchTerm := args[0].String()start := time.Now()matchedIDs := store.Index.Search(searchTerm)log.Printf("Search found %d documents in %v", len(matchedIDs), time.Since(start))var results []interface{}for _, id := range matchedIDs {results = append(results,map[string]interface{}{"title": store.Results[id].Title,"url": store.Results[id].URL,"id": store.Results[id].ID,})}// This will arrive as JSONreturn js.ValueOf(results)}// ..
Here's a high-level view of how everything fits together.
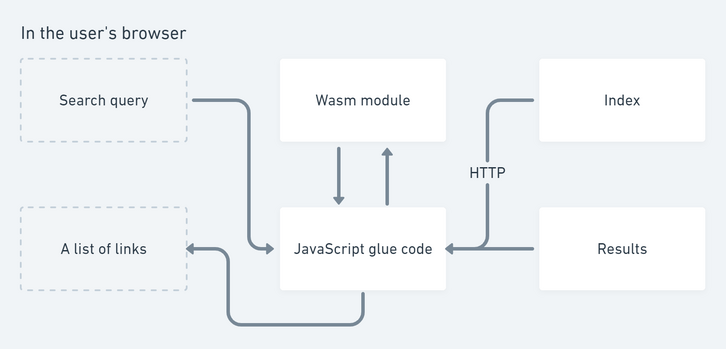
A JavaScript support file, wasm_exec.js, provides a Go class that connects JavaScript ⟷ Go. The Wasm module is loaded with WebAssembly.instantiateStreaming (polyfill available) and is passed to the Go instance. The store is downloaded via the Fetch API and is passed to the running Wasm module where the gob-encoded binary is decoded.
I wrote a ~50 line class that abstracts away most of this to make the project easier for a developer to interact with.
const crane = new Crane("crane.wasm", "federalist.crane");await crane.load()const results = crane.query('some keywords');console.log(results);
The result is, well, it's no Stork. But it works and it's fast. If there's one way to get a developer to respect the complexity of your project, have them build a technical demo of it with 1/50th of the features.

The binary is too large at around 3MB (but I didn't optimize for this). The solution for this is to read Reducing the size of Wasm files from the Go GitHub or read any of the blogs that come up when you search shrink go wasm binary. The best advice I found is to use TinyGo to generate the Wasm (the "Hello world" example is 575 bytes) and to limit the number of libraries you include. TinyGo actually artificially limits the libraries that you can use because it implements a subset of Go — which means the encoding/gob package is out (encoding/json too).
Design Problems
If there's one thing I learned, it's that search is a reasonably solved problem. It's easy to get started; stand on the shoulders of algorithms and away you go. The key problem in this space is the developer experience. Configuring the build process of a static site can be tricky when things beyond the standard content (e.g. posts, images) need to be generated. In order to return metadata about each result, these types of search tools require a config (usually TOML or JSON) and generating these files adds complexity.
Setting up a search bar with any features beyond the basics (e.g. auto-complete, full keyboard support, highlighted excerpts) is non-trivial too, especially when you want it to feel good and always react fast.
It's also hard to build a solution that solves all use cases. Every time a feature is added (e.g. zero tolerance for false positives, fuzzy search, excerpts, partial matching) the index size grows by an order of magnitude. One rather esoteric idea that I toyed around with was building a search solution that split the index depending on the letters the user entered. Having an index for all the words that start with a and one for b and so on. However, English letter frequency is weighted towards things like th (see English Letter Frequency Counts:
Mayzner Revisited).
There's also the issue of getting people to contribute to your project. Wasm is a reasonably young technology and building, testing, and debugging your code feels harder than it should be. Building a full-stack Wasm project always feels like it requires one-too-many steps. (For Go, it's worth calling out wasmbrowsertest that automates in-browser testing.)
In Introduction to WebAssembly, the best low-level introduction to the technology I've seen, Rasmus Andersson writes:
The web is an amazing concept that is currently falling short carrying a heavy legacy from the past. In order to bring truly great experiences to the web and blur the lines of what is and what isn’t a “native” experience, WebAssembly—or something else like it—needs to happen.
A search tool for static sites is a good fit for Wasm, and I hope to see projects in this space continue to evolve. It's a noble goal to build a project which actually has four design areas when you think about it:
- Back-end (build process)
- Back-of-the-front-end (search algorithm/Wasm)
- Front-of-the-front-end (results UI)
- Developer integration (APIs, docs)
So, thank your local open source developer today.
Stork GIF sourced from https://github.com/jameslittle230/stork