Dead links and images and be frustrating for visitors. Manually checking for them can be even more frustrating! We're going to build a bot that crawls a website for missing resources using just the Python standard library.
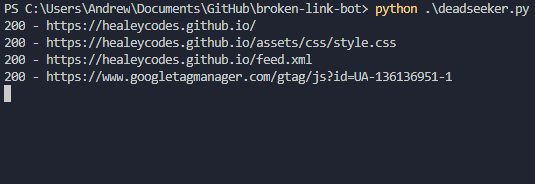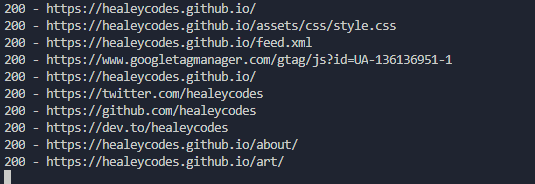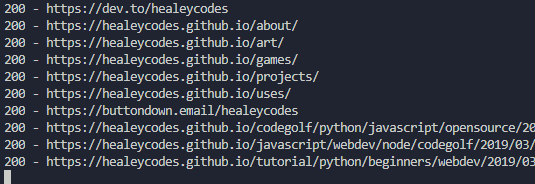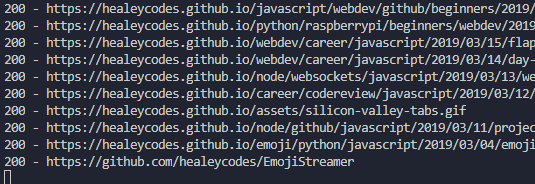
Let's talk design goals. We want to run a command and have the whole website checked for dead resources. This means some crawling will be involved.
$ python deadseeker.py 'https://healeycodes.com/'> 404 - https://docs.python.org/3/library/missing.html> 404 - https://github.com/microsoft/solitare2
More technically, the bot should parse all HTML tags on the given page looking for href and src attributes. If it finds any, it should send a GET request and log any HTTP error codes. If it finds local pages (e.g. /about/, /projects/) it should queue them to scan later. As we check links, let's add them to a set so we only check them once.
Python has html.parser for us — a simple HTML and XHTML parser. Let's take a look at how it works.
from html.parser import HTMLParser# extend HTMLParserclass MyHTMLParser(HTMLParser):# override `handle_starttag`def handle_starttag(self, tag, attrs):print(f'Encountered a start tag: {tag}')print(f'And some attributes: {attrs}')parser = MyHTMLParser()parser.feed('<html><body><a href="https://google.com">Google</a></body></html>')
This prints:
> Encountered a start tag: a> And some attributes: [('href', 'https://google.com')]
That's the heavy lifting handled for us. How about the requests? Python has urllib.request. It has urllib.request.urlopen which we'll use to send our GET requests. Most of the time you'll be using the third-party library requests but our requirements are slim enough that we can do it vanilla!
Let's check if Google is up, we're expecting a HTTP status code of 200 (OK).
>>> import urllib.request>>> r = urllib.request.urlopen('https://google.com')>>> r.status200
Some websites will return 403 (Forbidden) because our user agent will betray us as the bot we are. By default, it will look like User-Agent: Python-urllib/3.7. We can get around this by disguising ourselves with a different user agent. Responsible bots will check robots.txt to check the website's rules first!
We start with imports, grabbing everything we'll need. We also store a reference to a user agent string. This one means user is browsing on a recent Chrome build.
import sysimport urllibfrom urllib import request, parsefrom urllib.parse import urlparse, urljoinfrom urllib.request import Requestfrom html.parser import HTMLParserfrom collections import dequesearch_attrs = set(['href', 'src'])agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
We've also imported one data structure and declared another one — deque and set. deque is a 'list-like container with fast appends and pops on either end'. We'll use this as a simple queue — adding local pages as we find them and scanning them in a first-in-first-out manner. Our Set usage is simpler, we'll be checking if we've already sent a request to a link before doing so and adding it. We could have used a List in both instances but it would have less computationally efficient.
We extend the HTMLParser into LinkParser — the core of our program. We use super() to refer to the parent constructor that we're overriding.
class LinkParser(HTMLParser):def __init__(self, home):super().__init__()self.home = homeself.checked_links = set()self.pages_to_check = deque()self.pages_to_check.appendleft(home)self.scanner()
When we create an instance of this class we pass it the home page of our website. We store this as self.home so we can use it to check if a link we come across is a local page. As you can see at the end of the constructor, we start scanning right away — but what does 'scanning' mean?
def scanner(self):# as long as we still have pages to parsewhile self.pages_to_check:# take the first page addedpage = self.pages_to_check.pop()# send a request to it using our custom headerreq = Request(page, headers={'User-Agent': agent})res = request.urlopen(req)# check that we're about to parse HTML (e.g. not CSS)if 'html' in res.headers['content-type']:with res as f:# read the HTML and assume that it's UTF-8body = f.read().decode('utf-8', errors='ignore')self.feed(body)
As feed parses the HTML, it will encounter tags and call handle_starttag, handle_endtag, and other methods. We've overridden handle_starttag with our own method that checks the attributes for the keys we're looking for. When we come across <a href="http://google.com">Google</a> we want to extract the href value. Similarly for <img src="/cute_dog.png"> we want the src value.
def handle_starttag(self, tag, attrs):for attr in attrs:# ('href', 'https://google.com')if attr[0] in search_attrs and attr[1] not in self.checked_links:self.checked_links.add(attr[1])self.handle_link(attr[1])
Reminders: To loop through an iterable, you can use for thing in things: and in the following block, you refer to each item by the first variable, thing. To check whether something is in a set, you use item in a_set which returns a Boolean. You can add with a_set.add(item).
def handle_link(self, link):# check for a relative link (e.g. /about/, /blog/)if not bool(urlparse(link).netloc):# fix if we need to, we can't send a request to `/about/`link = urljoin(self.home, link)# attempt to send a request, seeking the HTTP status codetry:req = Request(link, headers={'User-Agent': agent})status = request.urlopen(req).getcode()# we're expecting errors (dead resources) so let's handle themexcept urllib.error.HTTPError as e:print(f'HTTPError: {e.code} - {link}') # (e.g. 404, 501, etc)except urllib.error.URLError as e:print(f'URLError: {e.reason} - {link}') # (e.g. conn. refused)# otherwise, we got a 200 (OK) or similar code!else:# remove this in production or we won't spot our errorsprint(f'{status} - {link}')# build a queue of local pages so we crawl the entire websiteif self.home in link:self.pages_to_check.appendleft(link)
A complete dead resource crawler in under 50 lines of vanilla code. Praise Python. Many people consider the expansive standard library to be one of the reasons for its popularity. The last thing we need to do is call our class, passing it the first argument after the script.
LinkParser(sys.argv[1]) # e.g. 'https://healeycodes.com/'
Here's the repository with the final code. The tutorial comments have been cleaned up. Happy botting 😀