- A dash of deep learning
- Automating GeoGuessr with Selenium
- Geolocation estimation
- Web demo
- The learnability of GeoGuessr
During this last lockdown in the UK, my wife and I have been playing GeoGuessr. It's slower paced than the computer games we normally play but it goes well with having an 11-week old baby who becomes more alive each and every day.
GeoGuessr is a geographic discovery game. You are dropped into a random Google Street View and tasked with pointing out your location on a map. You can look around, zoom, and follow the car's path through the local streets.
We've started to take the Daily Challenge on GeoGuessr quite seriously. We show up every day and push for a new high score. In the Daily Challenge there's a three minute limit per round which, for us, is either filled with frantic clicking as we zip through the Australian outback (probably while mistaking it for South Africa), or debating back and forth about whether ø exists in the Swedish language.
I now have a lot of I'll know it when I see it knowledge. I know Greenland on sight. My lost knowledge of country flags has returned, along with new knowledge of USA state flags, which countries drive on the right vs. left, which use KM vs M. I know pretty much every country-specific domain name (they're often on roadside adverts) – I won't forget .yu anytime soon.
Did you know that black and white guard rails are commonly found in Russia and Ukraine? Or that you can make out the blue EU bar on license plates through Google Street View's blurification? Read more in this 80,000 word guide – Geoguessr - the Top Tips, Tricks and Techniques.
The red and white striped arrow pointing downwards indicates that you are in Japan, most likely on the island of Hokkaido or possibly on the island of Honshu near mountains.

A dash of deep learning
I once read that machine learning is currently capable of doing anything a human can do in under one second. Recognize a face, pick out some text from an image, swerve to avoid another car. This got me thinking, and thinking led me to a paper called Geolocation Estimation of Photos using a Hierarchical Model and Scene Classification by Eric Müller-Budack, Kader Pustu-Iren, and Ralph Ewerth. This paper treats "geolocalization as a classification problem where the earth is subdivided into geographical cells."
It predicts the GPS coordinates of photos.
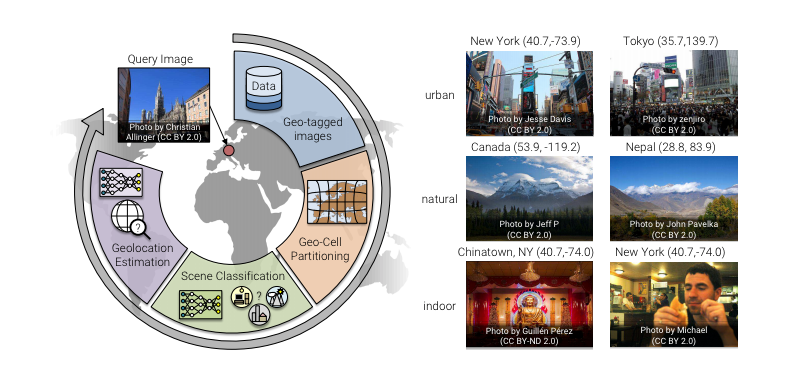
Even indoor photos! (GeoGuessr's Daily Challenge will often trap you inside a museum).
Recently, the paper's authors released a PyTorch implementation and provided weights of a pre-trained base(M, f*) model with underlying ResNet50 architecture.
I presumed that the pretrained model would not map well to the sections of photospheres that I could scrape from GeoGuessr. For training data, the authors used "a subset of the Yahoo Flickr Creative Commons 100 Million dataset (YFCC100M)". Which contains "around five million geo-tagged images from Flickr [and] ambiguous photos of, e.g., indoor environments, food, and humans for which the location is difficult to predict."
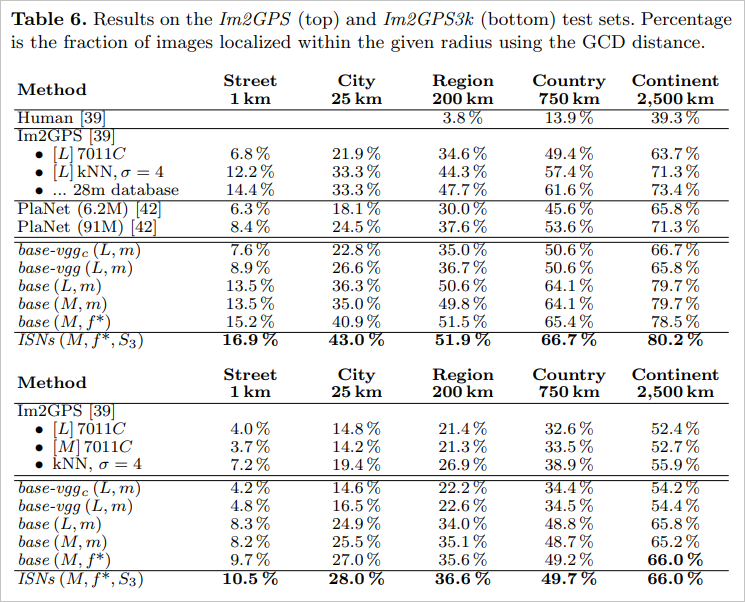
What was interesting was that on the Im2GPS dataset, humans found the location of an image at country granularity (within 750km) 13.9% of the time but the Individual Scene Networks were able to do it 66.7% of the time!
So the question became: who is better at GeoGuessr, my wife (a formidable player) or the machine?
Automating GeoGuessr with Selenium
To scrape screenshots of the current in-game location, I created a Selenium program that performs the following four times:
- Take a screenshot of the canvas
- Step forwards
- Rotate the view ~90 degrees
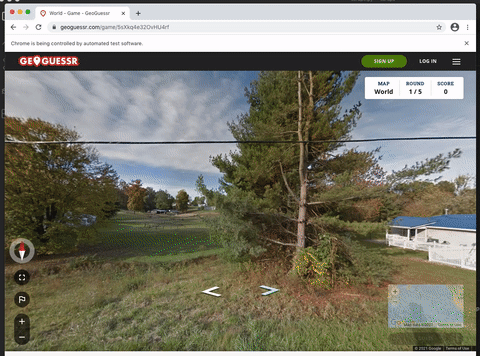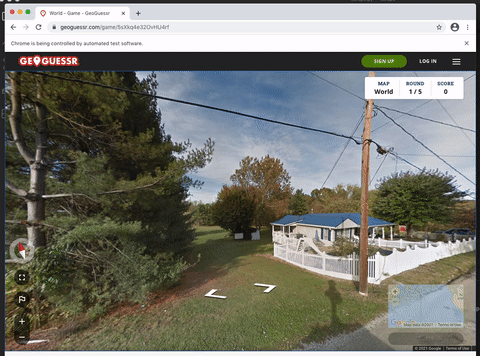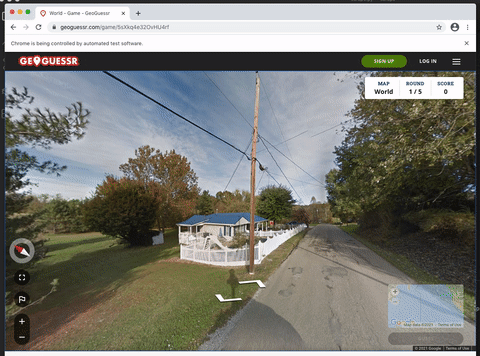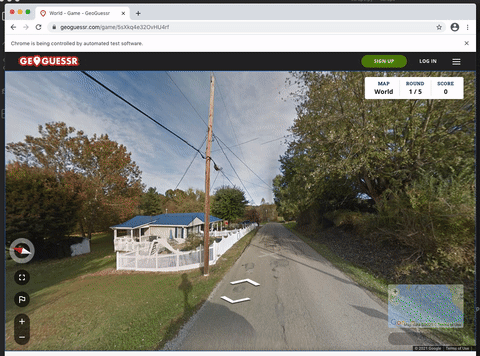
The number of times this happens is tuneable via NUMBER_OF_SCREENSHOTS in the snippet below.
'''Given a GeoGuessr map URL (e.g. https://www.geoguessr.com/game/5sXkq4e32OvHU4rf)take a number of screenshots each one step further down the road and rotated ~90 degrees.Usage: "python file_name.py https://www.geoguessr.com/game/5sXkq4e32OvHU4rf"'''from selenium import webdriverimport timeimport sysNUMBER_OF_SCREENSHOTS = 4geo_guessr_map = sys.argv[1]driver = webdriver.Chrome()driver.get(geo_guessr_map)# let JS etc. loadtime.sleep(2)def screenshot_canvas():'''Take a screenshot of the streetview canvas.'''with open(f'canvas_{int(time.time())}.png', 'xb') as f:canvas = driver.find_element_by_tag_name('canvas')f.write(canvas.screenshot_as_png)def rotate_canvas():'''Drag and click the <main> elem a few times to rotate us ~90 degrees.'''main = driver.find_element_by_tag_name('main')for _ in range(0, 5):action = webdriver.common.action_chains.ActionChains(driver)action.move_to_element(main) \.click_and_hold(main) \.move_by_offset(118, 0) \.release(main) \.perform()def move_to_next_point():'''Click one of the next point arrows, doesn't matter which oneas long as it's the same one for a session of Selenium.'''next_point = driver.find_element_by_css_selector('[fill="black"]')action = webdriver.common.action_chains.ActionChains(driver)action.click(next_point).perform()for _ in range(0, NUMBER_OF_SCREENSHOTS):screenshot_canvas()move_to_next_point()rotate_canvas()driver.close()
The screenshots will also contain the GeoGuessr UI. I didn't look into stripping it.
Geolocation estimation
I checked out the PyTorch branch, downloaded the pretrained model, and installed the dependencies via conda. I commend the repository's README. The requirements section was quite clear and I didn't run into any problems on a fresh Ubuntu 20.04 box.
I picked the World map on GeoGuessr for the showdown between human and machine. I gave the URL to my Selenium program and then ran inference against the four screenshots captured from GeoGuessr.
The machine's trimmed results are below.
python -m classification.inference --image_dir ../images/lat lngcanvas_1616446493 hierarchy 44.002556 -72.988518canvas_1616446507 hierarchy 46.259434 -119.307884canvas_1616446485 hierarchy 40.592514 -111.940224canvas_1616446500 hierarchy 40.981506 -72.332581
I presented the same four screenshots to my wife. She guessed a point in Texas. The actual starting location was over in Pennsylvania. The machine, indecisively, had four different guesses for each of the four screenshots. All of the machine's guesses were in the USA. Two very close ones and two further away.
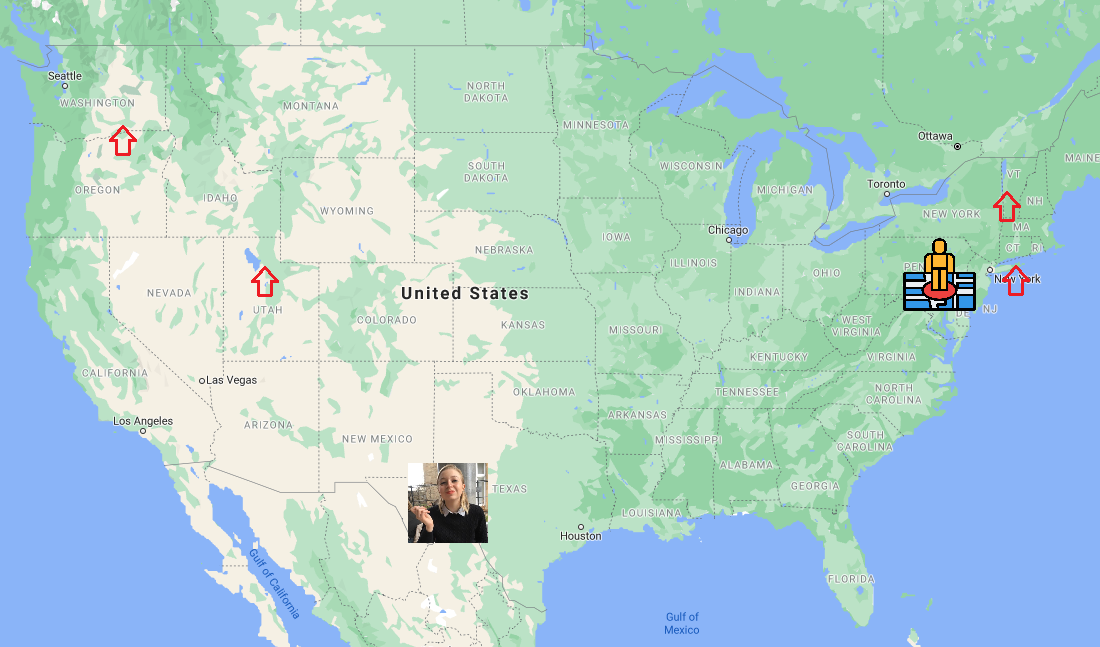
If we take the average location, the machine wins this round!
We played two more follow up rounds and the final results were 2-1 to the machine. The machine got quite close with a street in Singapore but failed to get anywhere near a snowy street in Canada (Madeline got the town in seconds).
I learned after writing this post that there's some fantastic prior art on machine vs. human on the battleground of GeoGuessr. In PlaNet - Photo Geolocation with Convolutional Neural Networks, Tobias Weyand, Ilya Kostrikov, and James Philbin also tried to determine the location of a photo from just its pixels.
To find out how PlaNet compares with human intuition, we let it compete against 10 well-traveled human subjects in a game of Geoguessr (www.geoguessr.com).
[H]umans and PlaNet played a total of 50 different rounds. PlaNet won 28 of the 50 rounds with a median localization error of 1131.7 km, while the median human localization error was 2320.75 km.
Web demo
The authors of Geolocation Estimation of Photos using a Hierarchical Model and Scene Classification built a pretty neat web-tool. Here I've run it against one of the Selenium screenshots.
A graphical demonstration where you can compete against the deep learning approach presented in the publication can be found on: https://tibhannover.github.io/GeoEstimation/. We also created an extended web-tool that additionally supports uploading and analyzing your own images: https://labs.tib.eu/geoestimation

The learnability of GeoGuessr
There are many reasons why trying to beat GeoGuessr (by which we mean out performing a human very often) with machine learning might be easier than locating any human-taken photo.
Compared to general geolocation estimation, in GeoGuessr we are (almost always) trying to find out which road we are on. This means more effort can be made into recognizing things which are always there – like road markings or car makes and models (both often betray a country). Effort could be made to travel down roads looking for road signs which provide the country's language or the signage text could be used to search a look-up table.
There are other markers, that some in the GeoGuessr community consider cheating, that a learning framework may pick up.
Looking downwards in street view will reveal part of the vehicle that captured the current photosphere. For example, in Kenya the front of the street view car has a black snorkel. Much of Vietnam was recorded on a motorbike and you can often see the rider's helmet. Countries are often covered by the same car with a unique color or antenna.

In other places, there are rifts in the sky where the photosphere stitching looks torn (largely in Senegal, Montenegro and Albania). Across Africa, there are sometimes escort cars that follow the street view car. There are different camera generations – with different resolutions, types of halo, colouring, and blurring at the bottom of the sphere. In the bottom corner of the photosphere there is the credit message – it usually has "Google" and a year but will occasionally have a photographer's name.
By exploiting these, I wouldn't be surprised if a machine could take down even the best GeoGuessrers in a timed competition. In fact, I'll go as far to say we are one research grant away from being categorically worse at GeoGuessr than machines.