In my last post, I introduced a text editor I’ve been working on called noter. It’s a piece of personal software, crafted for my own use cases like editing very small documents very quickly. To paraphrase this tweet, I want the applications I run to be malleable — I want to carve my own desire paths over time.
Since my last post, I’ve added three features; text highlighting, search, and a generic undo.
I’ll go over how each feature was implemented and some development strategies that have been working for me — and things that went wrong too!
Text Highlighting
Highlighting some text is kinda table stakes when it comes to text editing so I was pleased to see this feature land.
When the user holds Shift, and presses the right arrow twice, the two characters to the right of the cursor get a blue-y purple background during the next draw call. This background signifies to the user that these characters are highlighted and can be cut, copied, deleted via backspace, or replaced by new input.
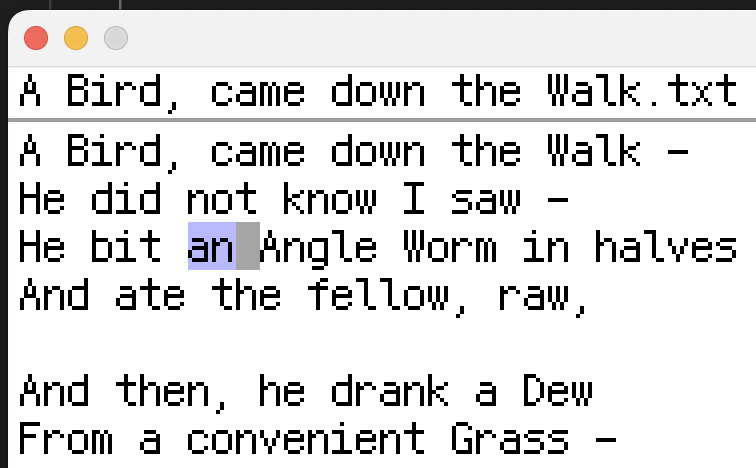
Whether a character is highlighted or not is stored on the editor object.
type Editor struct {// Line references and line positionshighlighted map[*Line]map[int]bool// ...}
Before the cursor moves, there’s a check to see if the Shift modifier is being held. If so, the character’s position is marked as highlighted.
Implementing this involved adding new lines amongst the existing movement logic. For the simple case of moving the cursor by a single column, the change was straight forwards.
if e.cursor.x < len(e.cursor.line.values)-1 {+ if shift {+ e.Highlight(e.cursor.line, e.cursor.x)+ }e.cursor.x++} else if e.cursor.line.next != nil {+ if shift {+ e.Highlight(e.cursor.line, len(e.cursor.line.values)-1)+ }e.cursor.line = e.cursor.line.nexte.cursor.x = 0}
Like most of the features I’ve added to the text editor, the trouble was solving for the edge cases. There are quite a few ways that the cursor can be moved like holding command to snap to the start and end of a line, or the start and end of the document. Or holding option to skip to the start and end of words.
One strategy for solving these edge cases, that’s been working quite well, is to refactor all actions to be as generic as possible — and to reuse code at all costs.
So, instead of snapping the cursor to the end of the line, I refactored the logic to be a loop that keeps stepping forwards, one character at a time, until the end of the line is reached. Each time I was able to make an action more generic, I reduced the number of edge cases that were required.
To render the blue-y purple highlight background, I copied the block of code that renders the cursor (which draws a gray background behind the font images).
The func (e *Editor) Draw function iterates over the lines of text and their characters. We first check if we need to render any highlighting, then if we need to render the cursor, and then the font image is drawn (or, if the space is empty, nothing is drawn).
// Loop over the characters in a viewable linefor x, char := range curLine.values[xStart:] {// ...// Render highlighting (maybe)if highlight, ok := e.highlighted[curLine]; ok {if _, ok := highlight[lineIndex]; ok {// Draw blue-y purple highlight backgroundebitenutil.DrawRect(screen,float64(x*xUnit)+screenInfo.xPadding,float64(y*yUnit)+screenInfo.yPadding,float64(xUnit),float64(yUnit),color.RGBA{0, 0, 200, 70,})}}// Render cursor (maybe)// ...// Render character (maybe)// ...
I also needed to implement some helper methods like: getting the highlighted characters (used for cut/copy), deleting a highlighted section (used for cut/backspace/replacing with new input), and also highlighting an entire line to the left or right of the cursor (used when holding Shift and pressing up/down to navigate to the next line), and selecting all (Command + A).
Of all the three features in this post, text highlighting was by far the easiest, and required the least amount of refactoring. It took about two hours from start to finish.
Text Search
(Command + F) enters search mode. During search mode, the top bar is replaced by a search box. After every keypress (or paste), any search results are highlighted with a lime-y green and the cursor is moved to the start of the first match. Enter, Tab, Up, and Down can be used to move through the matches.
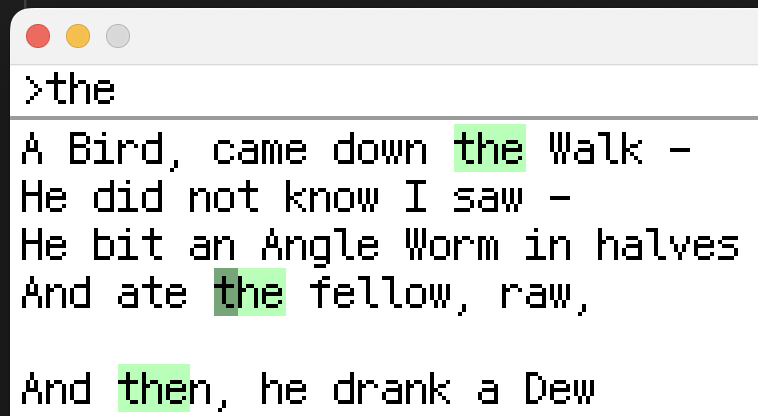
Before adding text search, all input was sent to the cursor’s position. So the first step I took was implementing two different modes; edit and search.
const (EDIT_MODE = iotaSEARCH_MODE)type Editor struct {mode uint// ...}
This allowed the existing input functions to be lightly modified by adding a check for the mode at the start of their logic. For example, all new characters flow through func (e *Editor) handleRune(r rune) so I added a check to pipe that input into the search box during search mode.
func (e *Editor) handleRune(r rune) {if e.mode == SEARCH_MODE {e.searchTerm = append(e.searchTerm, r)e.Search()return}// Otherwise, place the rune at the cursor's position, etc.// ...
The search function is 100 lines long and has too many responsibilities — but it works great so I’m writing about it now and then I’ll probably change it later.
Currently, it:
- Resets the search highlights from previous searches
- Finds matches, and
- Stores every character in a search highlights map
- Stores the match start in a different map (to support navigation)
- Moves to the start of a specific match based on the current tab index
As I wrote in my last post, the document’s state is stored in a doubly linked list of rune arrays. However, search matches can wrap over two lines if the user searches for a term with a new line character in the middle like my\ncat. This adds a little bit of complexity (I can’t just pull in a search library, or copy from ChatGPT).
The search function uses a naive search (a single linear scan rather than e.g. Boyer–Moore string-search) because it’s fast enough for now. It uses unicode.ToLower to match on both lower and upper case matches.
In pseudocode, the algorithm works like this.
While iterating over the entire document:When the first character of the search term is found,check if the rest of the search term follows it.If so, store the locations to be highlighted andstore the start of the match for tabbing.If there are search results:Move the cursor to the search result that matchesthe current tab index.Reset the tab index if it has wrapped around or if there are no matches.
To handle the search highlighting, I was able to use an existing pattern that renders the backgrounds for the cursor and text highlighting e.g. if some position is in some map then draw a rectangle with some color before the font image is rendered.
The search box reuses the logic for the top bar. All I needed to add was a check to see if we’re in search mode, if so: render the search term instead of the top bar.
Most of the bugs and edge cases with the search feature were either relating to search result tabbing, or making sure the concept of the new search mode was supported by all of the ways that input arrives in the document.
I’m glad I didn’t trying to introduce too much code structure during the early development of the text editor. Until I started adding features, like text search and undo, I didn’t really know what structure was needed.
Undo
(Command + Z) undoes a document mutation. It works like like most text editors — actions that enter, change, or remove text, can be reversed. To limit the scope of this feature, things like moving the cursor, or performing a search, can’t be undone.
The most naive way to implement undo would be to store a copy of the entire document whenever it’s changed. If the document was 1MB and the user typed hello, it would increase the programs memory use by 6!
I’m pretty happy with the current implementation of undo. It stores the opposite of the mutation and applies it when required. In the example above, where hello is undone, the current implementation wouldn’t need to store any additional text content in memory.
One initial idea that I discarded, was to calculate the difference between the start and end state of the document. While it was a cleaner abstraction, it was tricky to implement.
Like the other features I’ve written about here, I started by adding some global state to the editor object.
type Editor struct {undoStack []func() bool// ...}
undoStack is a stack of undo operations — functions that perform an inverse mutation. For example, if the mutation is “paste five characters” then the inverse is to “delete five characters starting at the end of the paste”.
The undo functions return a bool that indicates if the operation actually did something. This is because the initial mutation might have done … nothing. If the user hits backspace at the start of the document then nothing happens but an empty function is still added to the undo stack. The reason for this design choice was a) to not require the user to hit undo extra times and b) to keep the code simple.
Here’s the section of the update loop that handles undo:
// Undoif command && inpututil.IsKeyJustPressed(ebiten.KeyZ) {// ...// Loop until we perform an action that _does something_// or until we run out of things to undofor len(e.undoStack) > 0 {notNoop := e.undoStack[len(e.undoStack)-1]()e.undoStack = e.undoStack[:len(e.undoStack)-1]if notNoop {break}}return nil}
Inside the section of the update that handles backspacing, we can see how these undo functions are created and end up in the undo stack. In this case, we’re allow the user the option of undoing the the deletion of a single character.
if inpututil.IsKeyJustPressed(ebiten.KeyBackspace) {// ...// Append the undo function to the stacke.StoreUndoAction(// Perform a mutation and return a function// that performs the inverse mutatione.DeleteSinglePrevious())// ...return nil}
I’ll simplify the code of func (e *Editor) DeleteSinglePrevious to make it more clear what’s going on. As you’ll see, we need to perform the initial mutation first in order to know how to undo it. Being able to reuse all of the existing input functions as part of the undo logic reduced the chance of bugs (they’re either hardened by unit tests, or all of my manual testing).
func (e *Editor) DeleteSinglePrevious() func() bool {// Here's one case where an attempted mutation does nothing// so we push an empty undo operation onto the stackif e.cursor.line == e.start && e.cursor.x == 0 {// This is just `func() bool { return false }`return noop}// Perform the mutatione.deletePrevious()// Where did the cursor end up?lineNum := e.GetLineNumber()curX := e.cursor.xreturn func() bool {// Before performing the inverse mutation// we'll need to place the cursor backe.MoveCursor(lineNum, curX)// Use this core input function as if the user// is typing real characterse.handleRune(curRune)return true}}
My biggest mistake while adding this undo feature was trying to support undoing movement operations as well. I kept running into crashes (mostly because the cursor was left in non valid positions) because there’s many different types of movement; like search tabbing, moving a single character or multiple characters, moving words, and snapping to the start and end of the document.
I should have first researched how existing text editors handle undo operations, and also thought harder about what I want to happen when I need to undo something — I’m not trying to step back through everything that happened. I simply want to fix the document so I can continue writing.
I spent a few hours trying to implement redo but parked it for now. My thinking is that I’ll use the same strategies that I used for undo; I’ll reuse existing functions. If you think about it, a redo is just a copy of the initial mutation. Functions like func (e *Editor) DeleteSinglePrevious() should perform a mutation and return a redo function, and an undo function.
A few more things on the text editor roadmap that may or may not happen.
- Search and replacing
- Syncing to some online store of notes
- Supporting markdown syntax
- Adjusting window size from within the program
- Extracting the backend logic to it’s own library
As always, you can following the development on the noter repository.
Thanks to Samuel Eisenhandler for providing feedback on an early draft.