I normally write about completed projects. Ideas that I've turned into runnable programs.
There is a lot of hidden work in between my posts and projects. Hidden because the ideas are half-finished, or set aside because I got stuck and bored, or because I figured out that the thing was literally impossible.
Here's a selection of ideas that I explored this month but decided not to finish. The common adage about learning more from failure than success is true!
Profiling JavaScript Applications
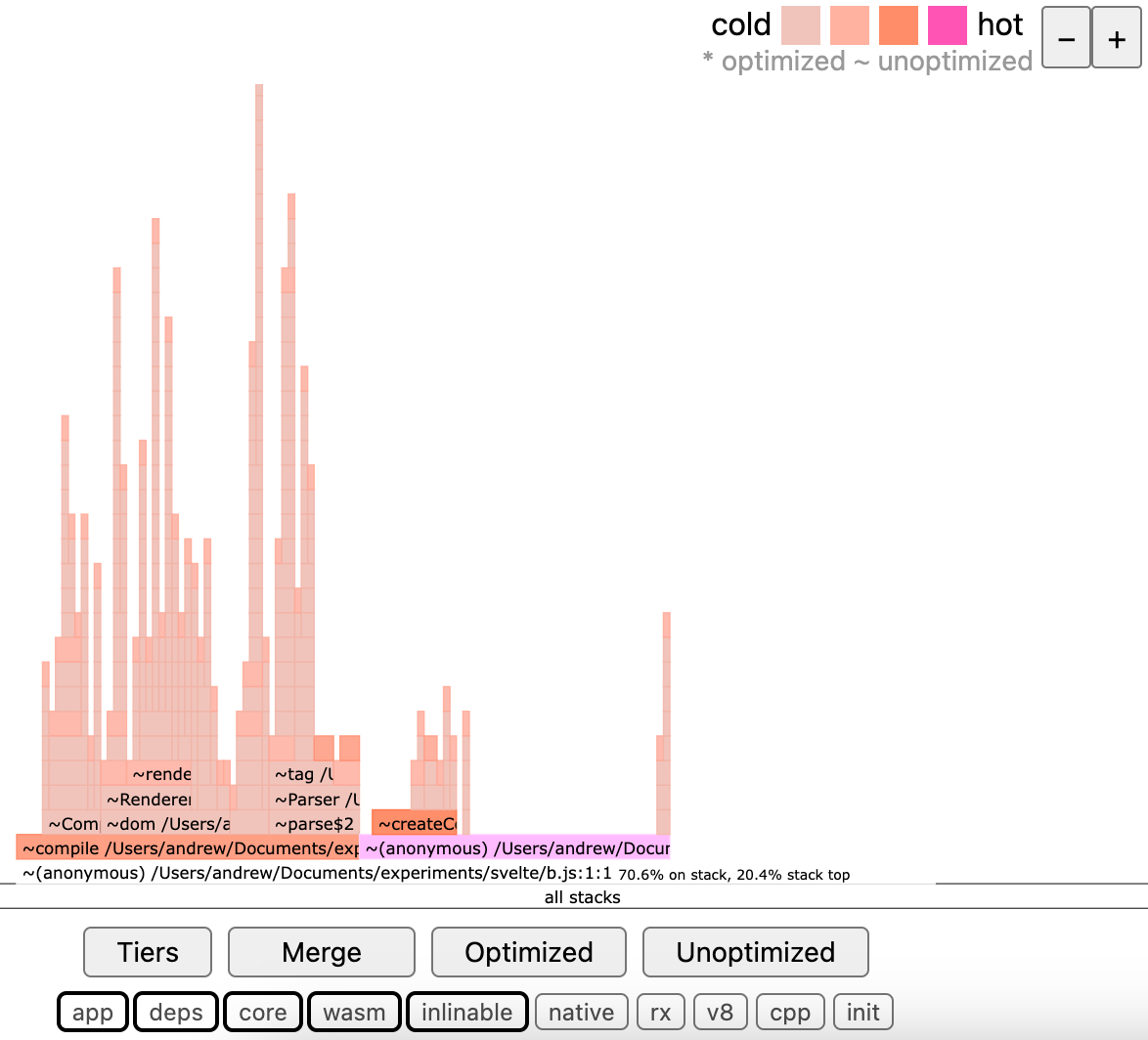
I played around with 0x, a command-line tool for producing an interactive flamegraph from a Node process. I wanted to write about how to profile code and look for bottlenecks but I wanted to show a real-life example by finding an optimization in an open source library.
I profiled the svelte compiler and found a potential micro-optimization. Specifically the clone utility adapted from lukeed/klona. In my tests it was slower than both JSON stringifying and parsing, and structuredClone. But making the code change isn't straight forward as the clone utility "[skips] function values in objects when cloning, so we don't break tests". I also didn't want to waste a maintainer's time by opening a PR without confidence it was actually a good idea.
I should have profiled my own projects where a) there would be more low-hanging fruit and b) I would have better knowledge about what kind of code changes are a good idea.
0x will profile and open a flamegraph when you run 0x -o my-app.js and they look like this:
Making a Fast HTTP Router
I've been following the Hono project — a small, simple, and ultrafast web framework — which claims to have the fastest JavaScript router. It actually comes with three router implementations.
Routers used in Hono are really smart.
SmartRouterautomatically picks the best router from the following three routers. Users can use the fastest router without having to do anything!
TrieRouter- Implemented with Trie tree structure.RegExpRouter- Match the route with using one big Regex made before dispatch.StaticRouter- Optimized for the static routing.
In the PR that added the one-big-regular-expression strategy, it was 11% faster than the existing tree-based router.
It will be a large regular expression, but since common prefixes can be grouped together by trie, I think it will grow slowly in the general case.
The paths:
- /help
- /:user_id/followees
- /:user_id/followers
- /:user_id/posts
- /:user_id/posts/:post_id
- /:user_id/posts/:post_id/likes
Turn into:
^/(?:help$()|([^/]+)/(?:followe(?:es$()|rs$())|posts(?:/([^/]+)(?:/likes$()|$())|$())))So, the recipe for fast routing is something like this: if you have static paths then use a dictionary, if you have many different paths then use a tree, if you have many similar paths (as most web applications do) use a regular expression.
I wanted to write about strategies for writing fast HTTP routers — a cool problem space which deals directly with data structures and algorithms. My idea was to write toy examples of HTTP routers that use ideas from Hono so I could dig into the details. However, I struggled getting the code to be a) approachable for someone not familiar with the problem space and b) not too many lines of code for a blog post.
Fuzzing JavaScript Applications
I used to think that fuzzing (or fuzz testing) was an advanced technique that required a bunch of pre-study. I'm not sure why I thought this. By reading some resources, I saw that it's actually quite accessible and the Hello, World is simple: throw random inputs at your API and see if it crashes or leaks memory. This is called black-box fuzzing because we aren't observing or acting on the program's internals. There are other types of fuzzing that are aware of program structure and generate inputs with an aim to cover every possible code flow.
Jsfuzz is one of the latter, it's coverage-guided.
Fuzzing for safe languages like nodejs is a powerful strategy for finding bugs like unhandled exceptions, logic bugs, security bugs that arise from both logic bugs and Denial-of-Service caused by hangs and excessive memory usage.
Here's an example from the docs, that the library authors used to find a crash in jpeg-js:
const jpeg = require('jpeg-js');function fuzz(buf) {try {jpeg.decode(buf);} catch (e) {// Those are "valid" exceptions. we can't catch them in one line as// jpeg-js doesn't export/inherit from one exception class/style.if (e.message.indexOf('JPEG') !== -1 ||e.message.indexOf('length octect') !== -1 ||e.message.indexOf('Failed to') !== -1 ||e.message.indexOf('DecoderBuffer') !== -1 ||e.message.indexOf('invalid table spec') !== -1 ||e.message.indexOf('SOI not found') !== -1) {} else {throw e;}}}module.exports = {fuzz};
In order to turn "JavaScript Fuzzing" into a post, I either wanted to a) learn enough about fuzzing to write meaningfully about it or b) discover a bug in an open source library.
I read about how SQLite does fuzzing, and did some of the fuzzing-project, but I felt like I had only scratched the surface of the topic. I fuzzed some libraries I use often (parsers, compilers, and chess utilities) but didn't find any bugs. So, no post.
Infinite Chess
Even though I am quite bad at chess, I very much enjoy playing it at lichess.org, making chess engines, playing chess variants, and following the scene. I also enjoy video games of all types.
I've had many ideas to build video games based on chess. These ideas fall into a few categories:
- Auto chess (like Dota Auto Chess but more like chess than Dota)
- Chess tower defence (you setup the pieces, and opponents attack in a simple manner)
- Agar.io but you are a ball of chess pieces rather than "matter"
I spent some time sketching out how chess tower defence might play out. I'm most inspired by the tower defence variants I played in Warcraft II growing up.
I started coding a prototype but I realised that I was building a complicated chess library from scratch. I couldn't use existing libraries because I had a non-standard board and entirely different game rules. Building games are fun because you can iterate and play them. I was disconnected from the playing part, so I paused the project for now.
Little Lisp Syntax Highlighter
One of my favorite programming language tutorials is Little Lisp interpreter by Mary Rose Cook, which walks you through building an interpreter for a minimal Lisp.
I'm familiar with the basics of syntax highlighting because I used Ink's syntax highlighter to add highlighting to code samples in my Ink guide, Ink by Example.
I had this wild idea to extend Little Lisp to be able to syntax highlight itself. But I quickly found that I was adding quite a lot to the language — and having no error reporting utilities (e.g. "there's an error on line X") made iterating on this project quite frustrating.
I've shelved this idea but I'm considering adding syntax highlighting to one of my own programming languages that do have error reporting (e.g. Adventlang).
Fin
I added quite a few things to my programming bag of tricks this month. Rather than going deep on a single idea, or shallow in many, I ended up in a happy medium zone — chugging along, gaining small insights, but without any a-ha moments. I consider this month to be a success.
It's been fun writing about things that I haven't finished. When I don't publish, it sometimes feels like wasted work. I wish that I was comfortable enough to tweet as I explored ideas and projects – rather than texting stream of conscious thoughts to my friends (you know who you are).
What ideas have you started and given up on? Let me know!